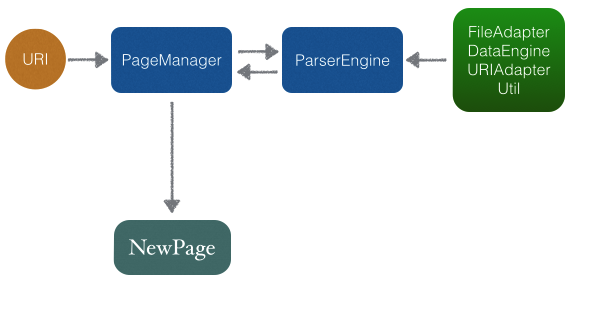
资源定位-页面管理器
页面管理器是一个用于触发和管理app内页面跳转展示的模块,通过该模块调用方可以很方便的触发页面的跳转并传递自定义的参数。将页面的切换操作抽象为一种URI触发机制,克服了不同页面对应不同VC(viewController)时跳转页面时的不灵活性。下面我们将页面跳转管理器统称为PM(Page Manager)
为什么PM?
在我们平时的应用开发过程中,我们应该都碰到过根据远程数据配置页面入口的情况,通常我们会枚举所有情况,根据不同的入参决定要切换到的页面和切换页面的形态,这样做一般会存在如下问题:
- 页面切换逻辑太过分散,不便管理维护
- 不同的触发位置都需要实现一份分发逻辑,造成大量的冗余代码
- 分发方法过于庞大,极大的影响可读性
- 运营位(数据)、动态入口配置不灵活
而PM的提出就是为了解决以前分散的页面跳转带来的不便,而将页面跳转统一成为一种URI的形式来做处理,这样实现的优势基本上归结为以下几点:
- 页面跳转(VC切换)抽象为一种URI,方便统一分发管理
- 可以避免在非主线程触发页面切换时引起的crash
- 统一的URI定位符处理,同时处理web页面和native页面的天然切换
- 对传入参数进行字符话处理,可以通过简单的URI初始化对象,而不需要关心具体的参数初始化,类似HTTP请求
- 使底层页面切换方法针对上层透明,接入方不需要关心是否是平台自身实现的容器VC
- 方便监控页面切换指数(性能等)
怎么实现?
这里我们可以思考下,当为了满足上述优势的情况下,该怎么实现?
首先,我们需要一个规则来映射到我们app中对应的VC;我们还需要一个业务模块来屏蔽app内页面的切换逻辑;还需要一个将映射规则解析成PM能懂的解析器;还需要一个调度页面跳转的核心模块,….
总结出来分为如下几个模块:
- 文件管理模块–>负责处理映射规则文件
- URI解析模块–>负责解析URI,将URI以我们定义的规则拆分,并提供获取相关信息的接口
- 数据工厂–>根据文件管理模块、URI解析模块输出产生PM能处理的数据
- 解析引擎–>负责调度处理文件管理模块、URI解析模块、数据工厂,获取合适的路径
- 业务模块–>负责告知PM,本地页面切换方式,用于屏蔽不同APP之间的差异
- 核心模块–>负责处理页面切换的核心逻辑
文件管理模块–FileAdapter
FileAdapter作为一个文件适配器,用来处理文件的获取(网络、bundle、缓存),并将文件输出为PM可识别的类型。并对外提供如下接口
//!配置文件名称,返回配置文件的绝对路径需要带上后缀名,也可直接从外部进行设置
@property (nonatomic,strong) NSString *configFilePath;
//!配置文件对应的数据,根据configfile文件的内容输入以字典形式输出,不同格式的数据文件需要经过转换整理成字典类型返回
- (NSDictionary *)configInfos;我们也可以在FileAdapter内做一些文件的获取逻辑和读取逻辑。
例如,在demo中,我们支持的文件类型是macox和iOS中最常见的plist类型,所以我们需要在FileAdapter中对plist文件进行解析,并转换成PageManager可识别的NSDictionary类型。如果我们的原文件是Json格式的话,我们只需要重新继承实现FileAdapter,对新有的逻辑进行处理即可
URI解析模块–URIAdapter
URIAdapter模块的主要工作就是根据我们的URI解析出我们需要的信息,通过URIAdapter,可以在URI提取出URI对应的host、pathComponent、parameters等信息
同FileAdapter一样,URIAdapter也可以理解为一个抽象的接口层,提供一个默认的URI解析规则,如果使用者需要适配以往的URI或者定义自身的URI拼接规则,指需要继承URIAdapter来实现自己的URIAdapter即可
URIAdapter为外部提供了如下接口:
//!要处理的URI数据,该URI定义页面跳转的数据
@property (nonatomic,strong) NSString *URI;
//!uri对应的host
@property (nonatomic,strong,readonly) NSString *host;
//!uri对应的PathComponent
@property (nonatomic,strong,readonly) NSArray *pathComponent;
//!uri对应的参数列表,以list的形式返回,item为dic数据详细格式参见定义
@property (nonatomic,strong,readonly) NSArray *parameters;这里需要对默认的URI拼接方式做一个说明,默认的URI结构如下
//默认的URI拼接方式,由协议头+host+pathComponent组成
xxxx://page.xx/hello?parameter1=x¶meter2=xx符合标准的URI定义格式,我们根据xxxx:(scheme)来区分应用,用page.xx(host)来区分模块,其他相应的模块来控制页面切换时的形态或者初始化参数
数据工厂–DataEngine
顾名思义,DataEngine是用于生产数据的模块,它根据FileAdapter和URIAdapter数据来生产页面跳转必须的业务数据,该模块主要负责产生页面跳转时必须的数据(参数、VC),并返回跳转路径
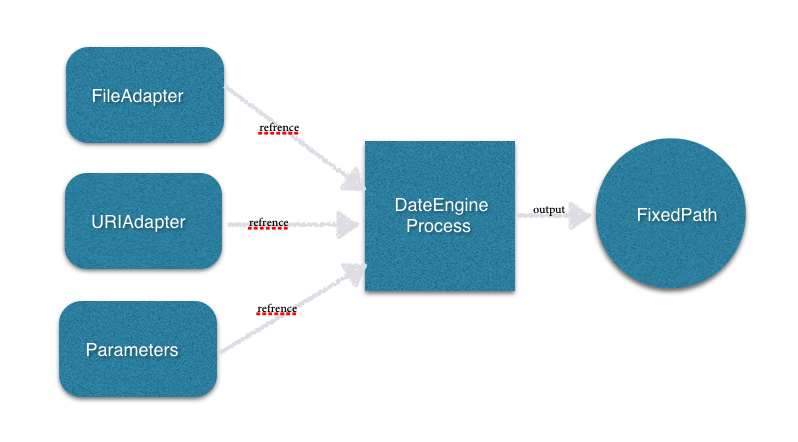 fixedPath是一个路径序列,每个item为一个ManagerPathNode对象
fixedPath是一个路径序列,每个item为一个ManagerPathNode对象
 数据工厂,还担负了校验参数的任务,负责校验必传参数是否传递了和参数格式是否正常等。如果不满足需求则数据工厂返回的fixedPath则为空
数据工厂,还担负了校验参数的任务,负责校验必传参数是否传递了和参数格式是否正常等。如果不满足需求则数据工厂返回的fixedPath则为空
解析引擎–PageManagerParserRuleEngine
解析引擎,很明显,作为一个引擎,负责联动各个模块完成由URI–>Data的任务。所以对于解析引擎来说,需要知道协同的模块都有哪些,这些协同模块是怎么工作的。解析引擎需要实现一个接口,使用者可根据自己的需求自定义自己的解析引擎。也可以将解析引擎单独拆分出来应用于其他模块
//!URI解析规则处理器需要实现的接口
@protocol CCPageManagerParserRuleEngineInterface<NSObject>
@optional
//!如果需要一个单例的页面规则解析器,请实现改方法,如果未实现该方法,系统会每次创建一个解析器的实例,且不长期拥有实例
+ (instancetype)engine;
@required
//!处理消息URL,该消息URL和参数的处理结果直接以block的形式反馈给receiver,flag类型参照CCPageManagerFlag
- (BOOL)handleUrl : (NSString *)url withParameters : (NSMutableArray *)parameters onCompletion : (void (^)(NSArray *path, CCPageManagerFlag flag)) completion;
//!是否能处理该类URL目前是否能处理,只针对域来处理而不做详细的跳转判断
- (BOOL)canOpenUrl : (NSString *)url;
@end业务模块
这里的页面模块指的是根具体使用方比较相关的部分。为了完成PM的可移植性,在初期对对具体平台相关的页面切换方法进行了包装,针对不同的业务场景我们只需要改变
这里我们对普通的VC做了如下抽象
- 针对NSObject对象实现了VC的接口,方便在自定义VC的应用中快速的移植
- 人为的VC区分为普通VC和容器VC(ContainerIViewController)
- 对VC实现页面切换操作接口
#pragma mark -CCPageManagerViewControllerInterface
//!view controller实现的接口
@protocol CCPageManagerViewControllerInterface <NSObject>
@required
//!当前的 view controller对象,容器vc的该方法返回当前展示的view controller,如果receiver不是一个容器vc,则应返回自身
- (id)currentViewController;
//!当前view controller 所属于的container,如果当前view controller为 app的root view controller的话,则返回nil
- (id)containerViewController;
//!当前view controller 对应的自view
- (UIView*)view;
@optional
//!在参数index位置显示viewcontroller,需要根据不同的容器做相应的实现,对应能支持的index操作才有作用,不支持的操作index则无忽略该参数
- (BOOL)showViewController : (CCPageManagerPathNode *)node atIndex : (NSUInteger)index;
//!dismiss当前的vc
- (BOOL)dismissViewController : (CCPageManagerPathNode *)node flag : (CCPageManagerFlag)flag;
@end
#pragma mark -CCPageManagerContainerInterface
//!容器vc接口类,对所有自定义container view controller都需要根据需求实现相应的方法,才能完成PageManager的功能
@protocol CCPageManagerContainerInterface <CCPageManagerViewControllerInterface>
@optional
//!容器view controller的子view controller们,若当前容器没有子view controller则返回nil,这里只对容器类的view controller支持该项操作,也可理解为人为的对将容器vc分离出来
- (NSArray *)childViewControllers;
@end这样做了以后,PM中对页面的调整和APP中页面的原生跳转逻辑成为了完全分离的。不依赖于任何系统原生的VC,可以屏蔽不同APP中的差异。当然在引入灵活性的同时也加大了嵌入PM的成本,我们需要为自己实现的容器VC实现响应的接口,来保证PM的功能完整性
核心模块–CCPageManager
该模块是整个PM的核心模块,或者说是中枢模块,用来驱动调配各个模块工作完成页面的跳转工作。为了让该模块正常工作,我们需要知道页面栈当前的状态和位置。所以需要提供一个初始化方法来获取rootViewController,而且提供一个出发页面跳转的方法。具体对外暴露了如下接口
@property (nonatomic,weak) id<CCPageManagerViewControllerInterface> rootViewController;
//!页面管理器操作的历史栈,该栈只针对经过页面管理器的操作做记录,没有经过页面管理器的操作不做记录,如要获取页面访问路径则需要保证页面的跳转是由页面管理器完成
@property (nonatomic,readonly,strong) CCPageHistoryStack *pageHistoryStack;
//!代理,详细可参见CCPageManagerDelegate
@property (nonatomic,weak) id<CCPageManagerDelegate> delegate;
#pragma mark -create instance
//!单例的页面管理器,需要调用页面管理器时请调用该单例,不要自己创建实例
+ (instancetype)defaultManager;
#pragma mark -规则解析器
//!注册URL解析规则器,具体实现参照CCPageManagerParserRuleEngineInterface的定义,返回值表示是否注册成功
- (BOOL)registerParserRuleEngineClassName : (NSString *)parserEngineClassName;
#pragma mark -页面调转消息处理
//!是否能处理该类URL目前是否能处理,只针对域来处理而不做详细的跳转判断
- (BOOL)canOpenUrl : (NSString *)url;
//!处理页面跳转消息,parameter为key、value形式
- (BOOL)openUrl : (NSString *)url withParameters : (NSArray *)parameters;
//!goback操作,调用可返回上次的页面,可以返回返回yes,反之返回NO,针对页面管理器跳转的pageHistoryStack完成一次回退操作,需要注意的是所有页面都采用页面管理器进行跳转时使用此方法才能获取到期望的结果
- (BOOL)goBack;
//!reset操作,对客户端来说,可以理解为跳转到root view controller
- (void)reset;辅助模块–util
该模块主要提供一些工具类,例如如何用序列化数据初始化一个对象等等。在PM中,最关键的初始化方法即属于该模块。关于实现方式在前面的文章中已经做了介绍,这里就不赘述
流程图
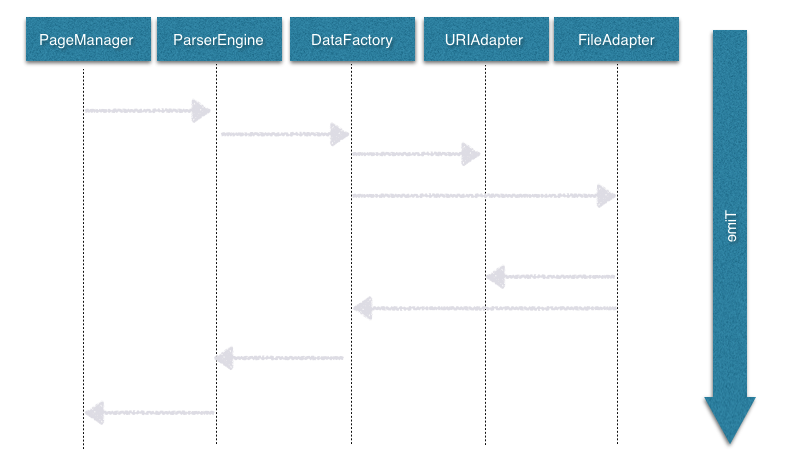
如何使用PM
在使用过程中,我们分为几种情况
引入PageManager到工程
1.如果我们的工程是以cocoaPods管理的,只需要在Podfile中加入
pod 'CCPageManager', '~> 0.0.1'2.如果我们是自行管理第三方代码的话,则需要手动将PageManager的framework引入工程
git clone git@codecooker.git完全使用PM的各个模块个解析规则
- 注册PM到应用
// 注册rootViewController给PM
[CCPageManager defaultManager].rootViewController = self.window.rootViewController;
//创建解析引擎
CCPageManagerParserRuleEngine *parserRuleEngine = [CCPageManagerParserRuleEngine new];
NSError *error = nil;
//设置解析引擎的过滤规则,示例的过滤规则为host=page.cc
NSString *pattern = @"(?<=://)page.cc(?=/)";
NSRegularExpression *expression = [[NSRegularExpression alloc]initWithPattern:pattern options:NSRegularExpressionCaseInsensitive error:&error];
if (!error) {
parserRuleEngine.filter = expression;
}
//注册解析引擎给PM
[[CCPageManager defaultManager]registerParserRuleEngine:parserRuleEngine];2 . 实现自己的FileAdatper,注册对应的映射文件
- (NSString *)configFilePath
{
//返回自身的配置文件路径
return [[NSBundle mainBundle]pathForResource:@"CCPageMap" ofType:@"plist"];
}
- (NSDictionary *)configInfos
{
//返回配置文件内的数据,格式参见附录,如需自定义格式,请继续向后看
return [NSDictionary dictionaryWithContentsOfFile:[self configFilePath]];
}3 . 构建自己的映射文件,如下形式
<key>betSsq</key>
<dict>
<key>class</key>
<string>CCViewController</string>
<key>attributes</key>
<array>
<dict>
<key>name</key>
<string>CCType</string>
<key>default</key>
<integer>1</integer>
<key>required</key>
<true/>
</dict>
<dict>
<key>name</key>
<string>playMethod</string>
<key>default</key>
<integer>-1</integer>
<key>required</key>
<true/>
</dict>
</array>
</dict>4.发送URI给PageManager
[self openUrl:message withParameters:array];改变规则后的调用
- 如果改变了URI解析规则,请重写URIAdapter中的方法,使之正确解析
- 如果改变了映射文件的格式,请重写FileAdapter中的方法
- 如果数据格式改变,请重写DataEngine中的方法
附录
1.Demo中配置文件的格式说明
<key>betSsq</key>
<dict>
<key>class</key>
<string>CCController</string>
<key>attributes</key>
<array>
<dict>
<key>name</key>
<string>CCType</string>
<key>default</key>
<integer>1</integer>
<key>required</key>
<true/>
</dict>
<dict>
<key>name</key>
<string>playMethod</string>
<key>default</key>
<integer>-1</integer>
<key>required</key>
<true/>
</dict>
</array>
</dict>key->页面标示符
class->对应页面viewController名称
attributes->参数列表,item为一个包含name和value的map
attributes[item]->name 表示参数的名称,可与viewcontroller中的property、instanceVariable对应
attributes[item]->value 表示与name对应的变量应初始化成的value,如果以URI的形式传递参数的话,只支持基础格式
attributes[item]->default 与name对应的变量如果为空时的默认值
attributes[item]->required 是否必传